Independent Software Vendor since 2001
consulting, software design and implementation
development of turn-key software solutions
support throughout the entire software lifecycle
Consulting, education and mentoring:
highly specialized and experienced in Oracle databases and systems managed services: from rack to application, Oracle Systems and Storage sizing and resale
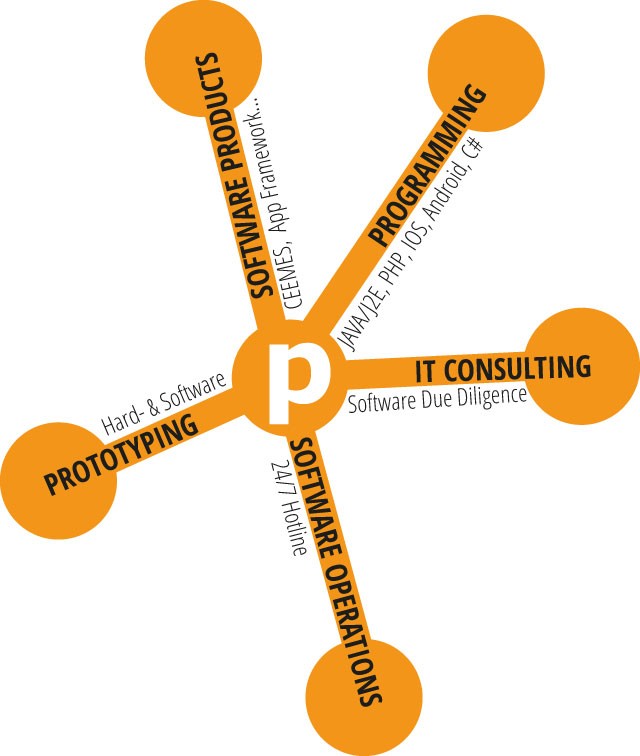
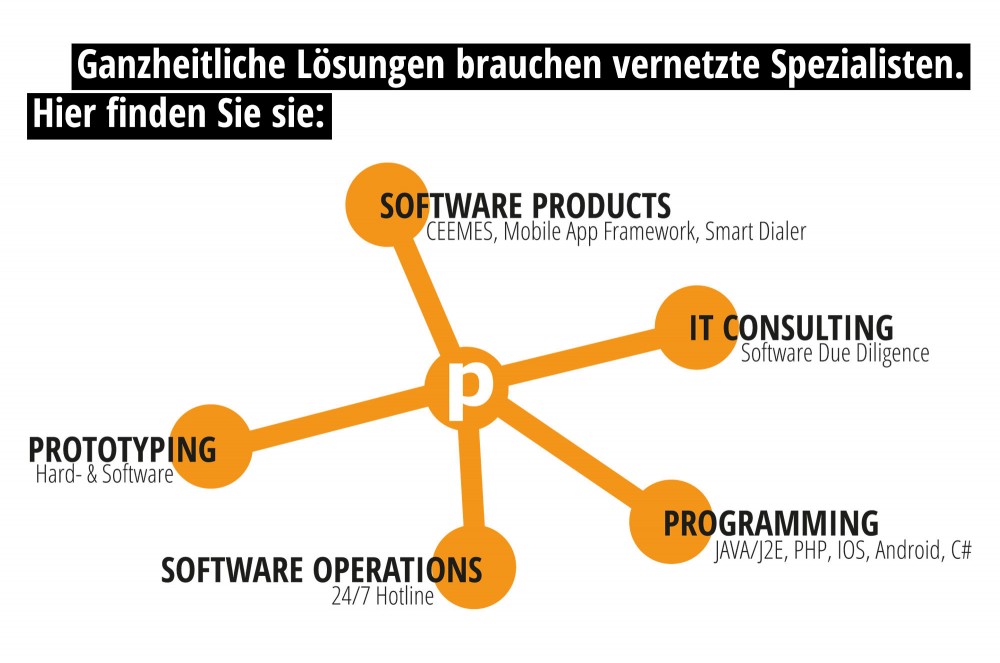

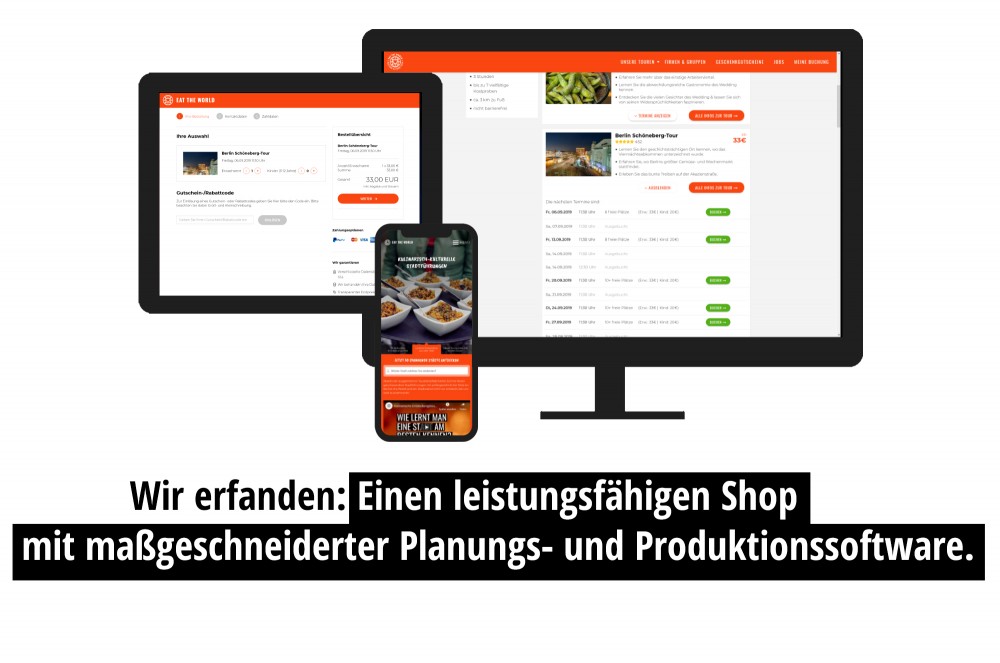

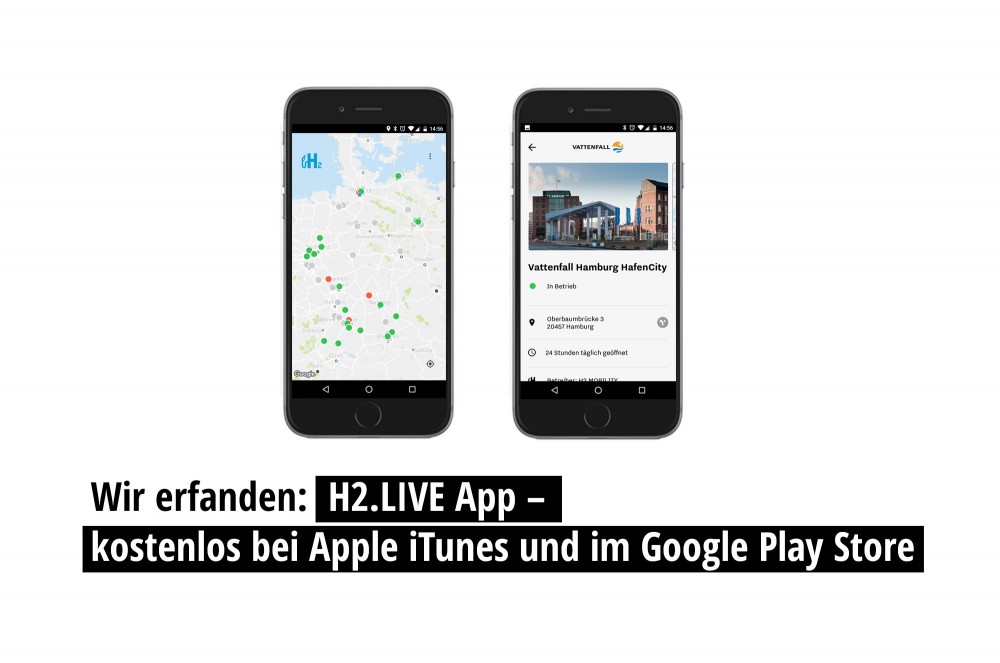










Seit dem Jahr 2001 konzipieren und entwickeln wir ganzheitliche Softwarelösungen für den Unternehmenseinsatz. Stets ausgerichtet an den spezifischen Bedürfnissen unserer Kunden. Ob zuverlässiges Steuerungssystem oder leistungsfähige Plattform, ob für softwaregestützte Start-ups, kleine Unternehmen oder internationale Konzerne: Im Rahmen unseres Beratungsansatzes lernen wir Ihre Anforderungen im Detail kennen, bringen unser Expertenwissen ein und lassen Sie von unserem großen Erfahrungshorizont profitieren.

Über uns
Vom Pionier zum Marktführer – ohne Bodenhaftung zu verlieren.
Innovationsgeist gepaart mit hanseatischer Verlässlichkeit, Zielstrebigkeit und Hands-on-Mentalität – das sind die Eigenschaften, die unser Unternehmen seit unserem Start im Jahr 2001 prägen. Mit über 30 festen Mitarbeitern am Standort Hamburg betreuen wir heute national und international tätige Kunden jeder Größenordnung.
Ein Erfolg, der ohne unsere eingespielten Projektteams undenkbar wäre. Bestehend aus Diplom-Informatikern, -Ingenieuren und Fachinformatikern sind unsere Teams jederzeit in der Lage, auch bei komplexen Projektanforderungen und unter Termindruck qualitativ hochwertige Softwareprodukte zu erzeugen.
Um einem internen Mangel an Fachkräften vorzubeugen, bildet portrix.net bereits seit dem Jahr 2005 zum Fachinformatiker aus. Momentan lernen bei uns zwei angehende Fachinformatiker mit Fachrichtung Anwendungsentwicklung sowie ein Fachinformatiker mit Fachrichtung Systemintegration sein Handwerk.
LEISTUNG
Wir können Ihnen maßgeschneiderte Lösungen liefern, die höchste Ansprüche an Qualität, Erweiterbarkeit sowie Verfügbarkeit erfüllen und zudem größtmögliche Benutzerfreundlichkeit bieten.
Unsere Services in den Bereichen Software Operations, Software Due Diligence und IT-Consulting komplettieren unser Angebot und machen uns zu einem Partner, der es versteht, auf jede Ihrer Fragen eine Antwort zu finden. Fordern Sie uns gern heraus.
AKTUELLE JOBS

KONTAKT
Sie befinden sich noch in der Planungsphase oder stehen vor einem akuten Problem?
Wir sind in jedem Fall für Sie da und freuen uns auf Ihre Kontaktaufnahme
portrix.net GmbH
Friesenweg 24
22763 Hamburg/Germany
Phone +49 40 3980530
Fax +49 40 39805329
Email: info@portrix.net
